[NLP] GLUE 데이터셋 구성
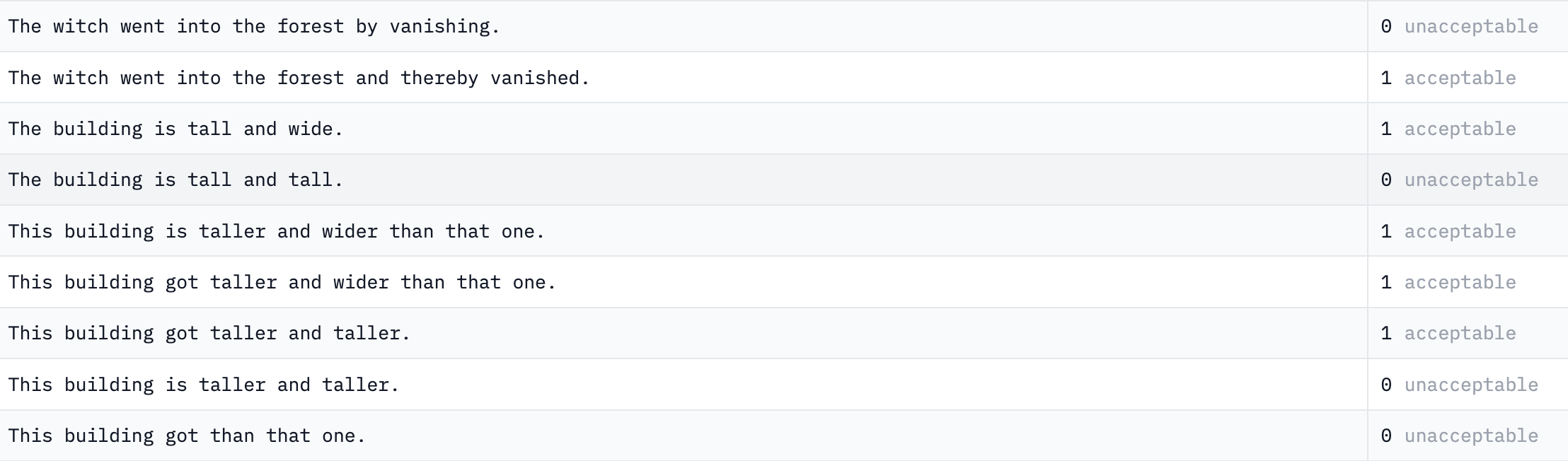
1) CoLA ( The Corpus of Linguistic Acceptability ) : 책과 신문 기사에서 가져온 데이터로, 문법적으로 옳은지 틀린지를 구분했다.
- 데이터 수 : 10.7k
- class : 2 ( acceptable : unacceptable = 70% : 30% )
2) MNLI ( Multi-Genre Natural Language Inference Corpus ) : 연설, 소설, 정부 보고서 등 다양한 출처로 구성. 전제(premise)와 가설(hypothesis)로 구성. 전제가 가설을 포함 (함의,entailment), 가설에 반하는지(모순,contradiction), 관련이 없는지(중립, neutral)
- 데이터 수 : 432k
- class 2 : ( 0 : 1 : 2 : 33.3% : 33.3% : 33.3% )
- 단순하게 설명하자면 entailment : 의미 동일, contradiction : 의미 반대, neutral : 의미 관계 없음



3) MRPC ( Microsoft Research Paraphrase Corpus ) : 온라인 뉴스 데이터. 의미가 동일한지로 구분.
- 데이터 수 : 5.8k
- class 2 : ( equivalent : 67%, unequivalent : 33% )

4) QNLI ( Question Natural Language Inference ) : SQuAD 의 이진분류 버전. question에 대해 paragraph 가 answer를 포함하는지 여부
- 데이터 수 : 116k
- class ( entailment : not entailment : 50% : 50% )

5) QQP ( Quora Question Pair ) : Quora website 에서 질문을 가져온 것. 두 질문의 의미가 동일한지 여부.
- 데이터 수 : 795k
- class ( not duplicate : duplicate : 63% : 37% )

6) RTE ( Recognizing Textual Entailment ) : series of annual textual entailment challenges 에서 가져옴. 데이터는 뉴스와 위키피디아 텍스트로 구성. 중립과 모순을 함의하지 않음으로 합친 데이터.
- 데이터 수 : 5.77k
- class : ( entailment : not entailment : 50% : 50% )

7) SST2 ( Stanford Sentiment Treebank ) : 영화 리뷰 데이터
- 데이터 수 : 70k
- class : ( positive : negative : 56% : 44% )

8) STSB ( Semantic Textual Similarity Benchmark ) : news headlines, video and image captions, and natural language inference data 에서 가져온 데이터. 의미 유사도 측정.
- 데이터 수 : 8.63k
- class : 1~5 소수 첫째자리까지 점수

9) WNLI ( Winograd NLI ) : 대명사가 포함된 문장을 읽고 대명사가 무엇인지를 파악하는 task 데이터. 함의 비함의로 나눔.
- 데이터 수 : 852
- class : ( not entailment : entailment : 51% : 49% )
