-
[NLP] BERT(1) 사전학습 Embedding카테고리 없음 2024. 4. 24. 20:22
1. BERT에 대해서
- BERT : Bidirectional Encoder Representations from Transformer
- Transformer 에서 Encoder 부분만을 이용한 모델이다.
- Google이 공개한 사전 훈련 모델이다. ( Wikipedia 25억 단어 + BooksCorpus 8억 단어 )
2. BERT 사전 학습 ( pre-training )
1) BERT Input Embedding
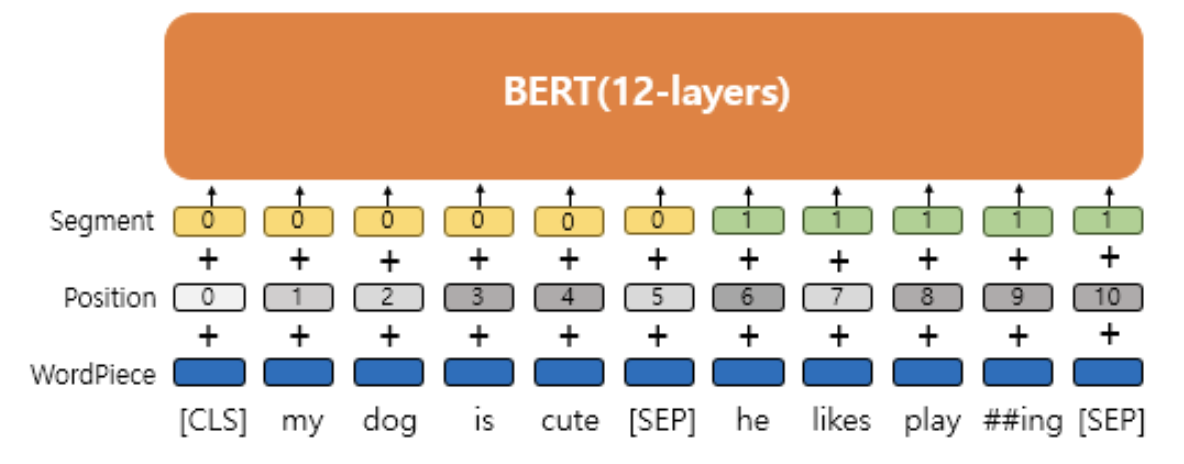

- BERT 모델 사전학습 시, Embedding 을 진행하는 과정이다.
- word_embeddings + position_embeddings + token_type_embeddings + LayerNorm + dropout 5가지 과정으로 구성된다.
i) word_embeddings = WordPiece Embedding
- BERT는 wordpiece tokenizer 를 이용한다.
- Vocab 의 size 는 32,000 이다.
- Embedding matrix ( 32000, 768 )로 token을 임베딩 시킨다.
- 이 Embedding matrix 가 역전파 과정에서 학습된다.
ii) position_embeddings
- 위치 정보를 embedding 화 하는 작업이다.
- transformer 에서는 사인&코사인 함수를 이용한 positional encoding 을 이용하지만, BERT 에서는 위치 정보 또한 학습 시킨다.
- BERT의 최대 입력 토큰 수는 512개 이므로, Embedding matrix (512, 768)을 학습시키게 된다.
iii) token_type_embeddings = Segment embedding
- 문장 순서를 구분해준다. ( 0, 1 사용하여 구분 )
-> word embedding + position embeddings + token_type_embeddings 세 임베딩 벡터를 더해준다.
iv) Layer Normalization
- 세 임베딩 벡터를 더한 결과에 LayerNorm 을 적용한다.
- LayerNorm 에 대해서는 따로 정리해 올리겠다.
iv) Dropout
- 과적합을 방지해주기 위해 일부 node를 0으로 만들어준다.